The General Data Protection Regulation turned eight years old in 2026. It was written when machine learning models were comparatively small and the idea of a conversational AI processing millions of personal data points in real time was science fiction. And yet, GDPR's principles map remarkably well onto LLM deployments — often in ways that create significant compliance problems for organizations using cloud AI APIs.
The Core GDPR Problem with Cloud LLMs
GDPR Article 5 lays out six principles for personal data processing. Let's walk through how cloud LLM APIs fare against each:
Lawfulness, fairness, and transparency. Do your users know their data is being sent to a third-party AI provider? Is there a lawful basis for that transfer? Many organizations deploying AI chatbots haven't thought carefully about whether they've disclosed this in their privacy notices.
Purpose limitation. Data collected for one purpose shouldn't be used for another. When a cloud provider uses your API queries to improve their model, is that consistent with the purposes for which your users gave you their data? Almost certainly not.
Data minimisation. You should only process data that is "adequate, relevant and limited to what is necessary." Sending full conversation histories to a cloud API when a summary would suffice violates this principle.
Accuracy. Less relevant for LLMs, but worth noting that AI-generated outputs can create inaccurate records if they're fed back into data systems.
Storage limitation. Data shouldn't be kept longer than necessary. Cloud providers' retention policies for API call logs may not align with your retention obligations.
Integrity and confidentiality. Appropriate security measures must be in place. Sending sensitive data over the internet to a foreign cloud provider introduces security surface that you don't control.
Article 28: Processor Agreements
If a cloud AI provider processes personal data on your behalf, they're a data processor under GDPR Article 28. You need a Data Processing Agreement (DPA) in place. Most major cloud providers offer standard DPAs, but these are often one-size-fits-all documents that don't address the specifics of LLM processing — particularly around model training.
Read the small print. Many DPAs explicitly carve out model training and improvement from their data processing restrictions. That carve-out means the provider can train on your users' data, and the DPA doesn't protect against it.
Cross-Border Transfers: Articles 44–49
Sending personal data to a provider in the US or elsewhere outside the EEA requires a legal mechanism under Chapter V of GDPR. The EU-US Data Privacy Framework covers many US transfers, but:
- It only covers providers certified under the framework
- It's been challenged legally and may be invalidated (as its predecessors were)
- It doesn't cover transfers to providers in other third countries
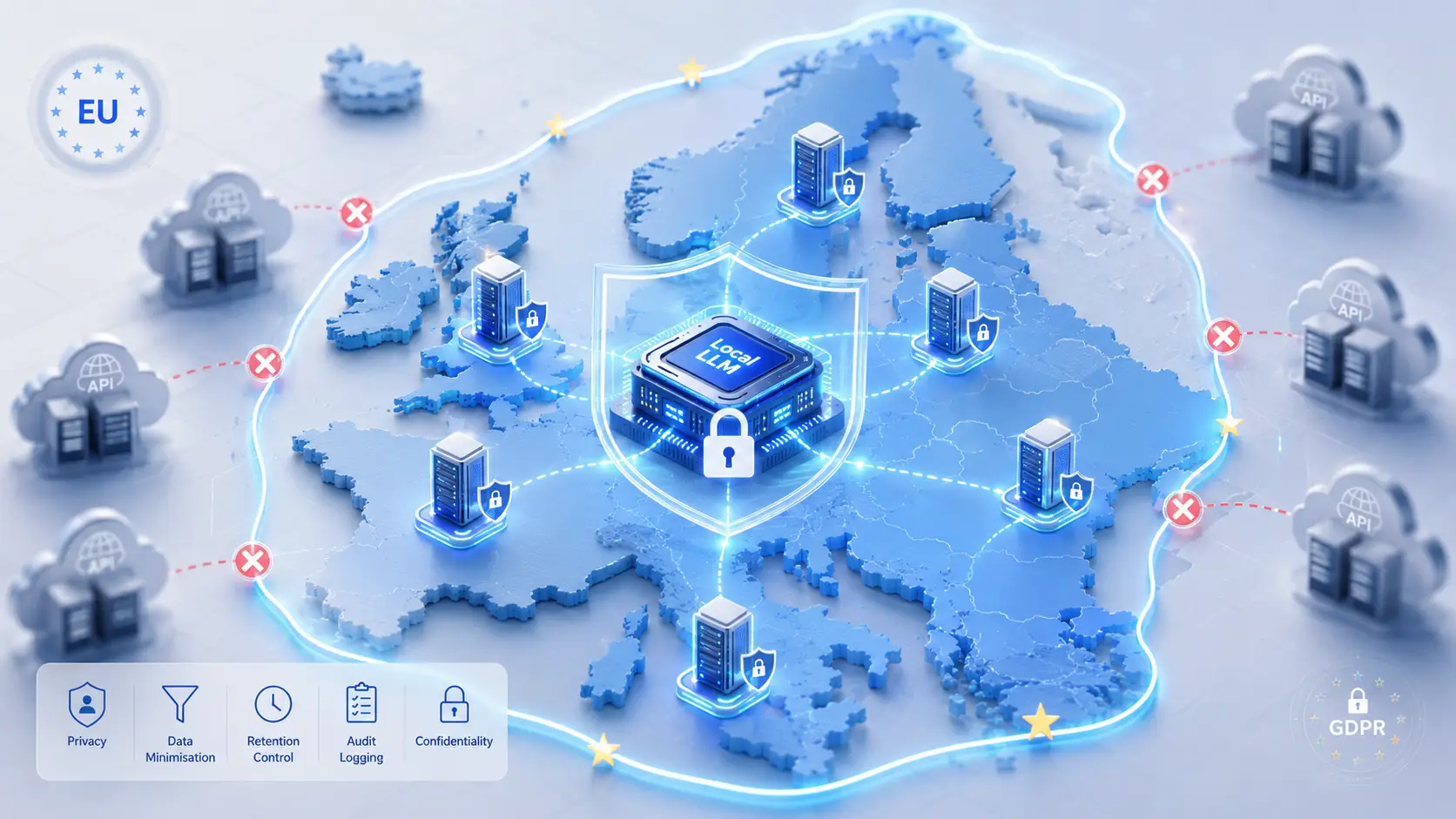
For organizations that can't tolerate transfer mechanism risk, the only certain solution is to keep processing within the EEA.
The Local LLM Answer
Running an LLM locally — on your own servers, in an EU data center — eliminates most of these problems structurally:
- No third-party processor. No DPA needed for the inference layer (you're the controller and processor).
- No cross-border transfer. Data never leaves the EEA.
- No training on your data. The model weights are static; your data doesn't feed back anywhere.
- Retention under your control. Logs are yours; retention policies apply as you configure them.
The remaining GDPR obligations — lawful basis, transparency, data subject rights — still apply. But you're not adding a whole layer of processor and transfer compliance on top.
Practical Considerations
Model selection. EULLM Hub provides pre-specialized models with AI Act compliance cards. Using a model with documented training data provenance is good practice for GDPR's accountability principle.
Audit logging. EULLM Engine includes built-in audit logging. Maintaining records of processing activities (Article 30) is straightforward when you control the inference stack.
Data subject requests. If a user asks what data you hold about them, or requests erasure, local infrastructure makes this tractable. You know exactly what's stored and where.
The bottom line: for organizations processing personal data with AI — which is almost every enterprise AI use case — local LLM infrastructure isn't just technically viable. In many contexts, it's the only GDPR-compliant option.
EULLM Engine runs entirely within your infrastructure. View the project on GitHub.