El Reglamento General de Protección de Datos cumplió ocho años en 2026. Se redactó cuando los modelos de aprendizaje automático eran comparativamente pequeños y la idea de una IA conversacional procesando millones de datos personales en tiempo real era ciencia ficción. Y sin embargo, los principios del RGPD se aplican de manera sorprendentemente directa a los despliegues LLM — a menudo de formas que generan problemas de cumplimiento significativos para las organizaciones que utilizan API de IA en la nube.
El problema fundamental del RGPD con los LLM en la nube
El artículo 5 del RGPD establece seis principios para el tratamiento de datos personales. Analicemos cómo responden a ellos las API LLM en la nube:
Licitud, lealtad y transparencia. ¿Saben sus usuarios que sus datos se envían a un proveedor de IA tercero? ¿Existe una base jurídica para esa transferencia? Muchas organizaciones que despliegan chatbots de IA no han reflexionado detenidamente sobre si han divulgado esto en sus políticas de privacidad.
Limitación de la finalidad. Los datos recopilados para una finalidad no deberían utilizarse para otra. Cuando un proveedor cloud usa sus consultas de API para mejorar su modelo, ¿es eso coherente con las finalidades para las que sus usuarios le facilitaron sus datos? Casi con toda certeza, no.
Minimización de datos. Solo deben tratarse los datos "adecuados, pertinentes y limitados a lo necesario." Enviar historiales de conversación completos a una API cloud cuando bastaría un resumen vulnera este principio.
Exactitud. Menos relevante para los LLM, pero conviene señalar que los resultados generados por IA pueden crear registros inexactos si se vuelcan en sistemas de datos.
Limitación del plazo de conservación. Los datos no deben conservarse más tiempo del necesario. Las políticas de retención de los proveedores cloud para los registros de llamadas a la API pueden no coincidir con sus obligaciones de conservación.
Integridad y confidencialidad. Deben aplicarse medidas de seguridad adecuadas. El envío de datos sensibles por internet a un proveedor cloud extranjero introduce una superficie de seguridad que usted no controla.
Artículo 28: Contratos de encargo del tratamiento
Si un proveedor de IA cloud trata datos personales por cuenta suya, es un encargado del tratamiento en virtud del artículo 28 del RGPD. Necesita tener un Acuerdo de Tratamiento de Datos (DPA) vigente. La mayoría de los grandes proveedores cloud ofrecen DPA estándar, pero suelen ser documentos uniformes que no abordan las especificidades del tratamiento por LLM — especialmente en lo relativo al entrenamiento de modelos.
Lea la letra pequeña. Muchos DPA excluyen explícitamente el entrenamiento y la mejora de modelos de sus restricciones de tratamiento de datos. Esa exclusión significa que el proveedor puede entrenar con los datos de sus usuarios, y el DPA no le protege frente a ello.
Transferencias transfronterizas: Artículos 44 a 49
El envío de datos personales a un proveedor en EE.UU. o en cualquier lugar fuera del EEE requiere un mecanismo jurídico al amparo del Capítulo V del RGPD. El Marco de Privacidad de Datos UE-EE.UU. cubre muchas transferencias a Estados Unidos, pero:
- Solo cubre a los proveedores certificados en el marco
- Ha sido impugnado jurídicamente y podría ser invalidado (como ocurrió con sus predecesores)
- No cubre las transferencias a proveedores en otros terceros países
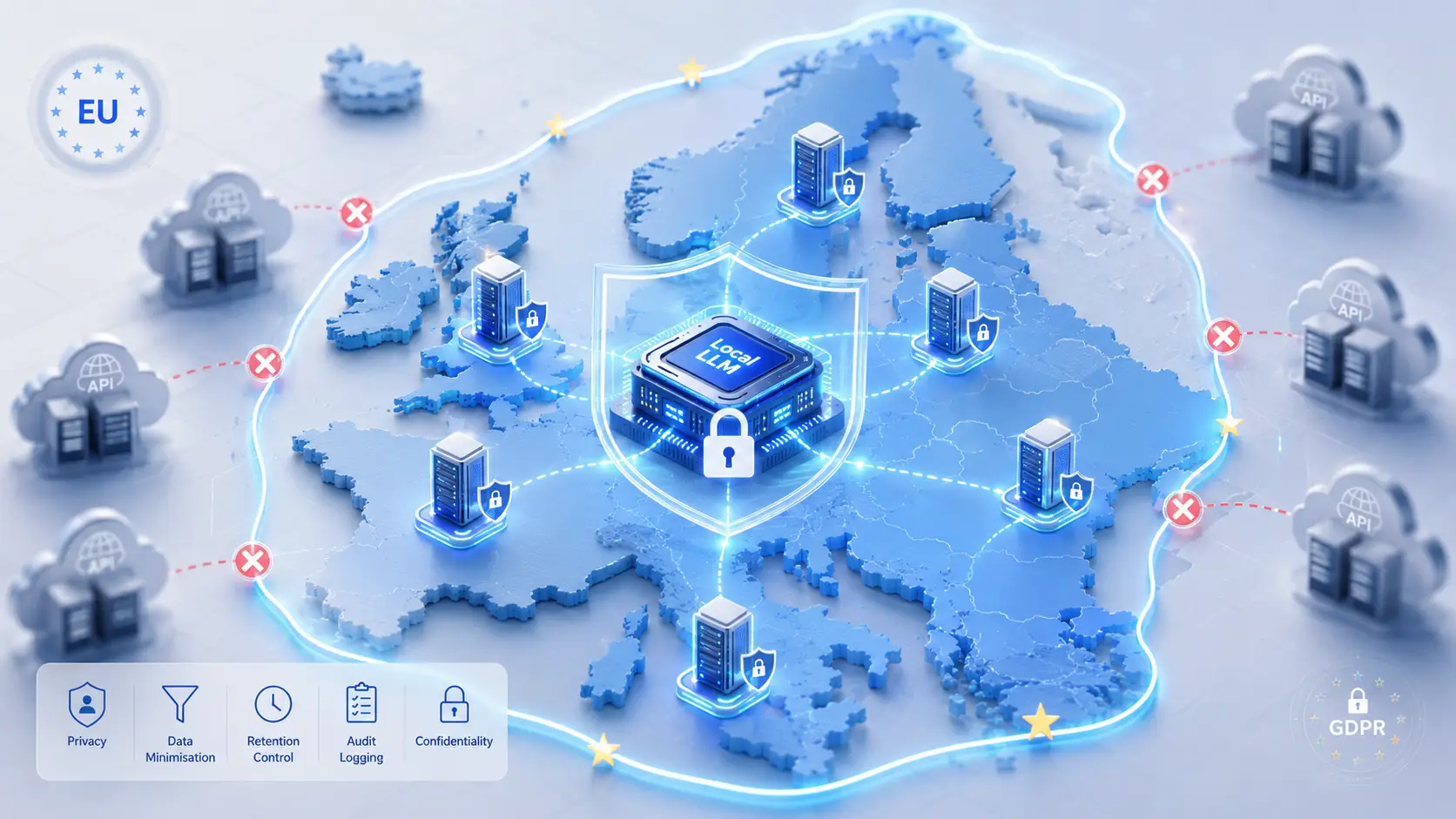
Para las organizaciones que no pueden tolerar el riesgo derivado de los mecanismos de transferencia, la única solución segura es mantener el tratamiento dentro del EEE.
La solución: LLM local
Ejecutar un LLM de forma local — en sus propios servidores, en un centro de datos de la UE — elimina estructuralmente la mayoría de estos problemas:
- Sin encargado del tratamiento externo. No se necesita DPA para la capa de inferencia (usted es a la vez responsable y encargado del tratamiento).
- Sin transferencia transfronteriza. Los datos nunca abandonan el EEE.
- Sin entrenamiento con sus datos. Los pesos del modelo son estáticos; sus datos no se retransmiten a ningún lugar.
- Conservación bajo su control. Los registros son suyos; las políticas de retención se aplican según su configuración.
Las obligaciones RGPD restantes — base jurídica, transparencia, derechos de los interesados — siguen aplicando. Pero no está añadiendo una capa entera de cumplimiento relativa al encargado y a las transferencias.
Consideraciones prácticas
Selección del modelo. EULLM Hub ofrece modelos preespecializados con fichas de conformidad con la AI Act. Utilizar un modelo con procedencia documentada de los datos de entrenamiento es una buena práctica en virtud del principio de responsabilidad proactiva del RGPD.
Registro de auditoría. EULLM Engine incluye registro de auditoría integrado. Mantener registros de las actividades de tratamiento (artículo 30) resulta sencillo cuando se controla la pila de inferencia.
Solicitudes de los interesados. Si un usuario solicita conocer qué datos dispone usted sobre él, o pide su supresión, la infraestructura local hace esto viable. Usted sabe exactamente qué está almacenado y dónde.
La conclusión: para las organizaciones que tratan datos personales con IA — lo que engloba prácticamente todos los casos de uso empresarial de IA — la infraestructura LLM local no es solo técnicamente viable. En muchos contextos, es la única opción conforme con el RGPD.
EULLM Engine se ejecuta íntegramente dentro de su infraestructura. Ver el proyecto en GitHub.