Il Regolamento Generale sulla Protezione dei Dati ha compiuto otto anni nel 2026. È stato scritto quando i modelli di machine learning erano comparativamente piccoli e l'idea di un'AI conversazionale che elaborasse milioni di dati personali in tempo reale era fantascienza. Eppure, i principi del GDPR si applicano ai deployment LLM in modo sorprendentemente preciso — spesso creando problemi di compliance significativi per le organizzazioni che usano API AI in cloud.
Il problema GDPR di fondo con i cloud LLM
L'articolo 5 del GDPR stabilisce sei principi per il trattamento dei dati personali. Vediamo come se la cavano le API LLM cloud rispetto a ciascuno.
Liceità, correttezza e trasparenza. I tuoi utenti sanno che i loro dati vengono inviati a un provider AI di terze parti? Esiste una base giuridica per quel trasferimento? Molte organizzazioni che deployano chatbot AI non hanno riflettuto abbastanza su se e come abbiano comunicato questo nelle loro informative sulla privacy.
Limitazione della finalità. I dati raccolti per uno scopo non dovrebbero essere usati per un altro. Quando un cloud provider usa le tue query API per migliorare il proprio modello, è coerente con le finalità per cui i tuoi utenti ti hanno fornito i dati? Quasi certamente no.
Minimizzazione dei dati. Dovresti trattare solo i dati che sono "adeguati, pertinenti e limitati a quanto necessario." Inviare interi storici di conversazioni a un'API cloud quando basterebbe un riassunto viola questo principio.
Esattezza. Meno rilevante per gli LLM, ma vale la pena notare che gli output generati da AI possono creare registrazioni inaccurate se vengono reimmessi nei sistemi dati.
Limitazione della conservazione. I dati non dovrebbero essere conservati più a lungo del necessario. Le politiche di retention dei cloud provider sui log delle chiamate API potrebbero non allinearsi con i tuoi obblighi di conservazione.
Integrità e riservatezza. Devono essere in atto misure di sicurezza adeguate. Inviare dati sensibili via internet a un cloud provider straniero introduce una superficie di sicurezza che non controlli.
Articolo 28: gli accordi con i responsabili del trattamento
Se un provider AI in cloud tratta dati personali per tuo conto, è un responsabile del trattamento ai sensi dell'articolo 28 del GDPR. Hai bisogno di un Data Processing Agreement (DPA). La maggior parte dei grandi provider offre DPA standard, ma spesso si tratta di documenti generici che non affrontano le specificità del trattamento tramite LLM — in particolare riguardo al training del modello.
Leggi la stampa fine. Molti DPA escludono esplicitamente il training e il miglioramento del modello dalle restrizioni sul trattamento dei dati. Quella clausola significa che il provider può addestrare sui dati dei tuoi utenti, e il DPA non protegge contro questo.
Trasferimenti transfrontalieri: articoli 44–49
Inviare dati personali a un provider negli USA o altrove fuori dal SEE richiede un meccanismo giuridico ai sensi del Capitolo V del GDPR. Il Data Privacy Framework UE-USA copre molti trasferimenti verso gli USA, ma:
- Copre solo i provider certificati nell'ambito del framework
- È stato contestato legalmente e potrebbe essere invalidato (come i suoi predecessori)
- Non copre i trasferimenti verso provider in altri paesi terzi
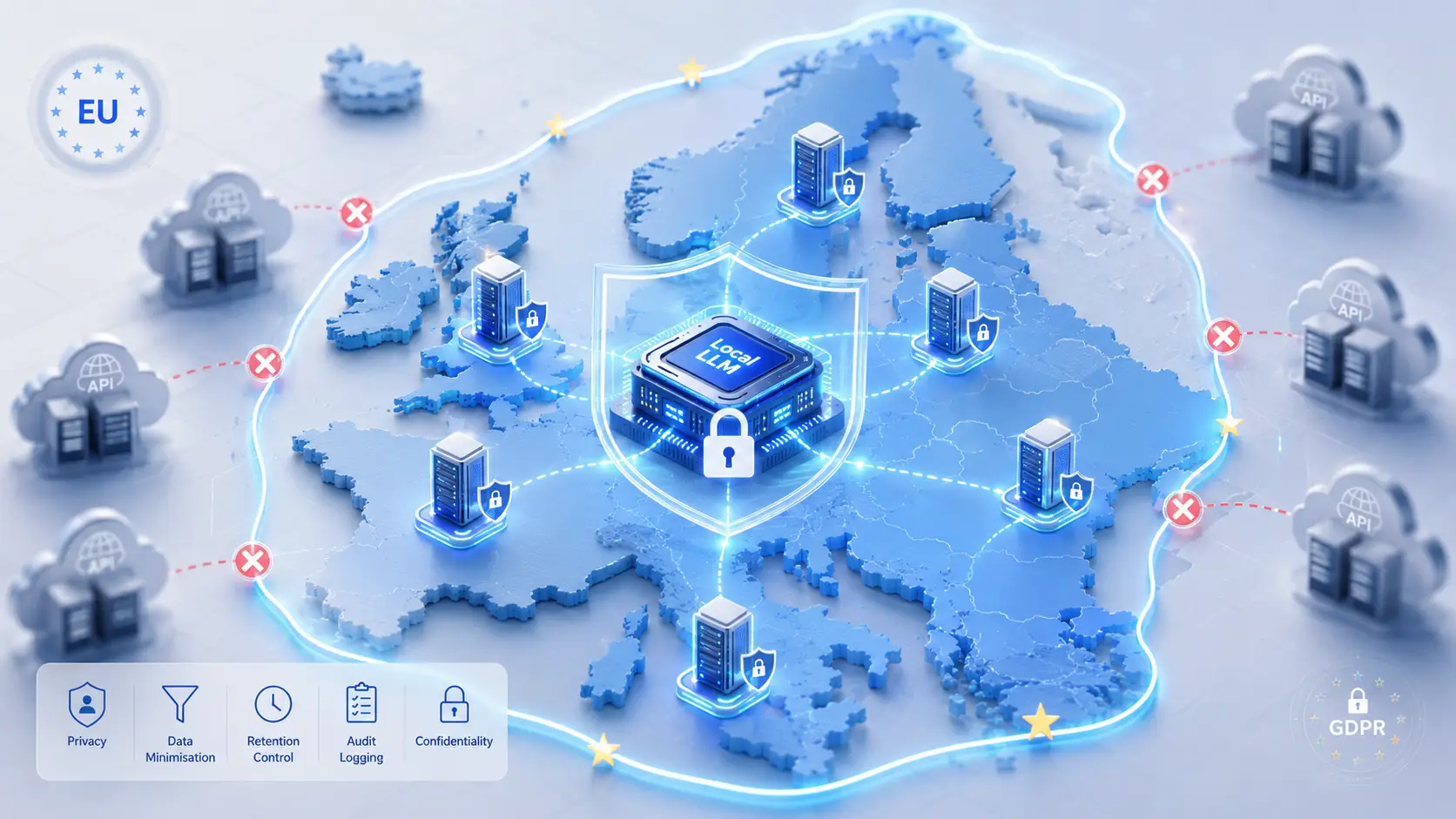
Per le organizzazioni che non possono tollerare il rischio legato ai meccanismi di trasferimento, l'unica soluzione certa è mantenere il trattamento all'interno del SEE.
La risposta: LLM in locale
Eseguire un LLM in locale — sui propri server, in un data center nell'UE — elimina strutturalmente la maggior parte di questi problemi:
- Nessun responsabile del trattamento terzo. Non serve un DPA per lo strato di inferenza (sei tu il titolare e il responsabile).
- Nessun trasferimento transfrontaliero. I dati non escono mai dal SEE.
- Nessun training sui tuoi dati. I pesi del modello sono statici; i tuoi dati non finiscono da nessuna parte.
- Retention sotto il tuo controllo. I log sono tuoi; le politiche di conservazione si applicano come le configuri.
Gli obblighi GDPR rimanenti — base giuridica, trasparenza, diritti degli interessati — si applicano comunque. Ma non aggiungi un intero strato di compliance su responsabili del trattamento e trasferimenti sopra a tutto il resto.
Considerazioni pratiche
Selezione del modello. EULLM Hub mette a disposizione modelli pre-specializzati con schede di conformità AI Act. Usare un modello con provenienza documentata dei dati di training è buona pratica per il principio di accountability del GDPR.
Audit logging. EULLM Engine include logging di audit integrato. Tenere i registri delle attività di trattamento (articolo 30) è immediato quando controlli lo stack di inferenza.
Richieste degli interessati. Se un utente chiede quali dati detieni su di lui, o richiede la cancellazione, l'infrastruttura locale rende tutto gestibile. Sai esattamente cosa è archiviato e dove.
La conclusione è questa: per le organizzazioni che trattano dati personali con l'AI — il che significa quasi ogni caso d'uso AI enterprise — l'infrastruttura LLM locale non è solo tecnicamente praticabile. In molti contesti, è l'unica opzione conforme al GDPR.
EULLM Engine gira interamente all'interno della tua infrastruttura. Vedi il progetto su GitHub.