De Algemene Verordening Gegevensbescherming werd in 2026 acht jaar oud. Ze werd geschreven toen machine learning-modellen relatief klein waren en het idee van een conversationele AI die miljoenen persoonlijke gegevenspunten in realtime verwerkt, science fiction was. Toch sluiten de principes van de GDPR opmerkelijk goed aan op LLM-implementaties — vaak op manieren die aanzienlijke complianceproblemen creëren voor organisaties die cloud AI-API's gebruiken.
Het Kernprobleem van de GDPR met Cloud LLM's
GDPR Artikel 5 legt zes beginselen vast voor de verwerking van persoonsgegevens. Laten we doorlopen hoe cloud LLM-API's scoren op elk beginsel:
Rechtmatigheid, behoorlijkheid en transparantie. Weten uw gebruikers dat hun gegevens worden verzonden naar een externe AI-provider? Is er een rechtsgrond voor die overdracht? Veel organisaties die AI-chatbots inzetten, hebben er niet goed over nagedacht of ze dit hebben bekendgemaakt in hun privacyverklaringen.
Doelbinding. Gegevens die voor één doel zijn verzameld, mogen niet voor een ander doel worden gebruikt. Wanneer een cloudprovider uw API-query's gebruikt om zijn model te verbeteren, is dat in overeenstemming met de doelen waarvoor uw gebruikers u hun gegevens hebben gegeven? Vrijwel zeker niet.
Gegevensminimalisatie. U mag alleen gegevens verwerken die "toereikend, ter zake dienend en beperkt zijn tot wat noodzakelijk is." Het versturen van volledige gespreksgeschiedenissen naar een cloud-API wanneer een samenvatting voldoende zou zijn, schendt dit beginsel.
Juistheid. Minder relevant voor LLM's, maar het is de moeite waard op te merken dat door AI gegenereerde uitvoer onjuiste records kan creëren als deze terug worden gevoerd in gegevenssystemen.
Opslagbeperking. Gegevens mogen niet langer worden bewaard dan noodzakelijk. Het bewaarbeleid van cloudproviders voor API-aanroeplogboeken komt mogelijk niet overeen met uw bewaarverplichtingen.
Integriteit en vertrouwelijkheid. Er moeten passende beveiligingsmaatregelen van kracht zijn. Het verzenden van gevoelige gegevens via internet naar een buitenlandse cloudprovider introduceert een beveiligingsoppervlak dat u niet beheerst.
Artikel 28: Verwerkersovereenkomsten
Als een cloud AI-provider persoonsgegevens namens u verwerkt, is dat een verwerker in de zin van GDPR Artikel 28. U heeft een Verwerkersovereenkomst (DPA) nodig. De meeste grote cloudproviders bieden standaard DPA's aan, maar dit zijn vaak documenten-voor-iedereen die de specifieke aspecten van LLM-verwerking niet behandelen — met name rond modeltraining.
Lees de kleine lettertjes. Veel DPA's sluiten modeltraining en -verbetering expliciet uit van hun verwerkingsbeperkingen. Die uitzondering betekent dat de provider op de gegevens van uw gebruikers kan trainen, en de DPA biedt daartegen geen bescherming.
Grensoverschrijdende Overdrachten: Artikelen 44–49
Het verzenden van persoonsgegevens naar een provider in de VS of elders buiten de EER vereist een juridisch mechanisme op grond van Hoofdstuk V van de GDPR. Het EU-VS Data Privacy Framework dekt veel overdrachten naar de VS, maar:
- Het dekt alleen providers die gecertificeerd zijn onder het kader
- Het is juridisch aangevochten en kan ongeldig worden verklaard (zoals zijn voorgangers)
- Het dekt geen overdrachten naar providers in andere derde landen
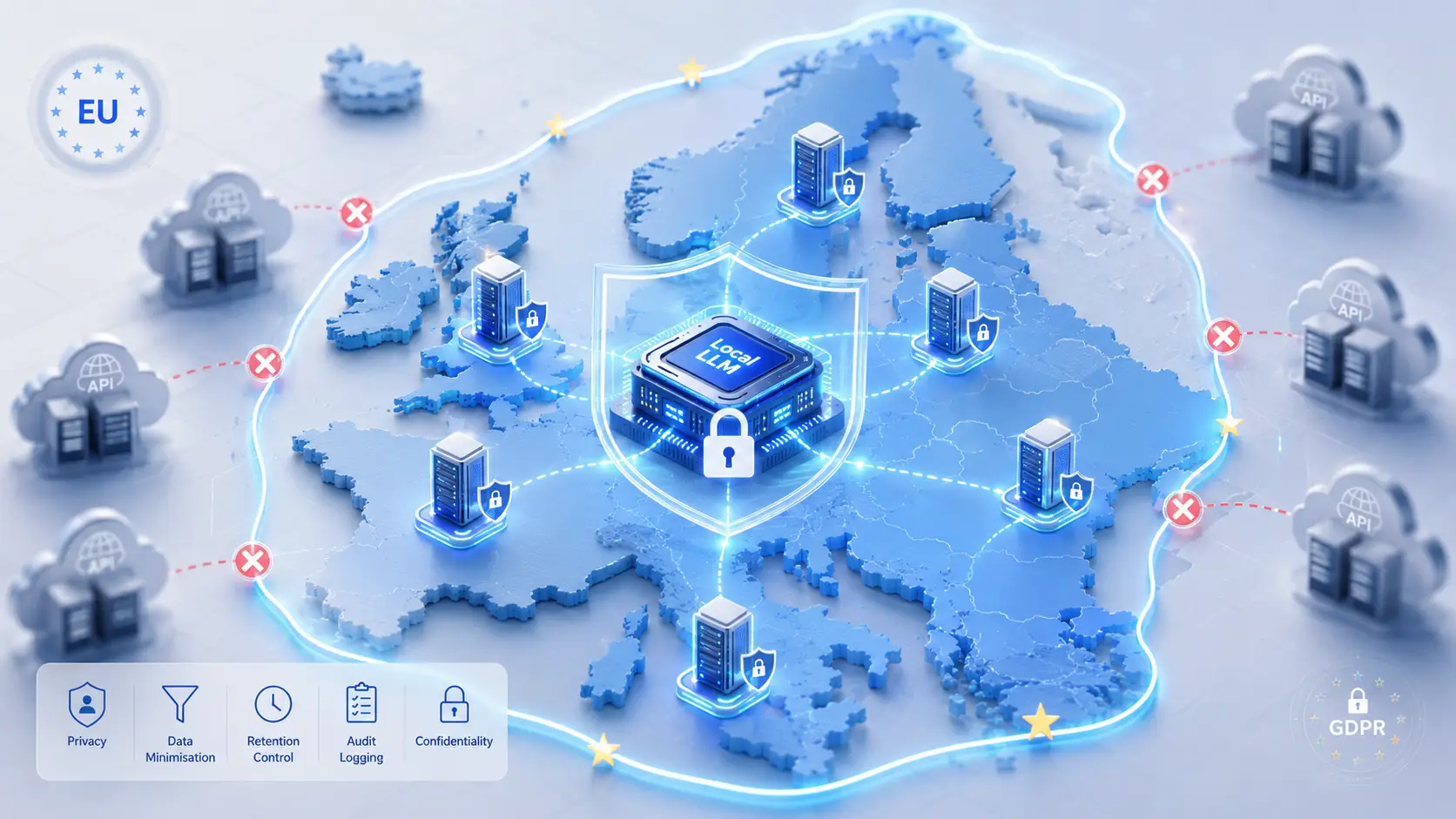
Voor organisaties die het risico van overdrachtsmechanismen niet kunnen tolereren, is de enige zekere oplossing om verwerking binnen de EER te houden.
Het Antwoord: Lokale LLM
Een LLM lokaal draaien — op uw eigen servers, in een EU-datacenter — elimineert structureel de meeste van deze problemen:
- Geen externe verwerker. Geen DPA nodig voor de inferentielaag (u bent zowel verwerkingsverantwoordelijke als verwerker).
- Geen grensoverschrijdende overdracht. Data verlaat de EER nooit.
- Geen training op uw data. De modelgewichten zijn statisch; uw data stroomt nergens naartoe terug.
- Opslag onder uw controle. Logs zijn van u; bewaarbeleid past u toe zoals u het configureert.
De overige GDPR-verplichtingen — rechtsgrond, transparantie, rechten van betrokkenen — zijn nog steeds van toepassing. Maar u voegt geen hele laag van verwerkers- en overdrachtscompliance toe.
Praktische Overwegingen
Modelselectie. EULLM Hub biedt vooraf gespecialiseerde modellen met AI Act compliance-kaarten. Het gebruik van een model met gedocumenteerde herkomst van trainingsdata is een goede praktijk voor het GDPR-verantwoordelijkheidsbeginsel.
Auditlogging. EULLM Engine bevat ingebouwde auditlogging. Het bijhouden van verwerkingsactiviteiten (Artikel 30) is eenvoudig wanneer u de inferentie-stack beheert.
Verzoeken van betrokkenen. Als een gebruiker vraagt welke gegevens u over hem bewaard of om wissing verzoekt, maakt lokale infrastructuur dit uitvoerbaar. U weet precies wat er is opgeslagen en waar.
Conclusie: voor organisaties die persoonsgegevens verwerken met AI — wat vrijwel elke zakelijke AI-toepassing omvat — is lokale LLM-infrastructuur niet alleen technisch haalbaar. In veel contexten is het de enige GDPR-conforme optie.
EULLM Engine draait volledig binnen uw infrastructuur. Bekijk het project op GitHub.