O Regulamento Geral sobre a Proteção de Dados completou oito anos em 2026. Foi redigido quando os modelos de machine learning eram comparativamente pequenos e a ideia de uma IA conversacional a processar milhões de pontos de dados pessoais em tempo real era ficção científica. No entanto, os princípios do GDPR aplicam-se de forma notavelmente eficaz às implementações de LLM — frequentemente de formas que criam problemas significativos de conformidade para organizações que utilizam APIs de IA em cloud.
O Problema Central do GDPR com LLMs em Cloud
O Artigo 5.º do GDPR estabelece seis princípios para o tratamento de dados pessoais. Vejamos como as APIs de LLM em cloud se saem em cada um:
Licitude, lealdade e transparência. Os seus utilizadores sabem que os seus dados estão a ser enviados para um fornecedor de IA terceiro? Existe uma base jurídica para essa transferência? Muitas organizações que implementam chatbots de IA não ponderaram cuidadosamente se divulgaram isso nos seus avisos de privacidade.
Limitação da finalidade. Os dados recolhidos para uma finalidade não devem ser utilizados para outra. Quando um fornecedor de cloud utiliza as suas consultas à API para melhorar o seu modelo, isso é compatível com as finalidades para as quais os seus utilizadores lhe forneceram os seus dados? Quase certamente não.
Minimização dos dados. Deve tratar apenas dados que sejam "adequados, pertinentes e limitados ao que é necessário." Enviar históricos completos de conversas para uma API em cloud quando um resumo seria suficiente viola este princípio.
Exatidão. Menos relevante para LLMs, mas vale a pena notar que os resultados gerados por IA podem criar registos inexatos se forem reinseridos em sistemas de dados.
Limitação da conservação. Os dados não devem ser conservados mais tempo do que o necessário. As políticas de retenção dos fornecedores de cloud para os registos de chamadas à API podem não estar alinhadas com as suas obrigações de retenção.
Integridade e confidencialidade. Devem estar em vigor medidas de segurança adequadas. O envio de dados sensíveis pela internet para um fornecedor de cloud estrangeiro introduz uma superfície de segurança que não controla.
Artigo 28.º: Contratos de Subcontratante
Se um fornecedor de IA em cloud tratar dados pessoais em seu nome, é um subcontratante ao abrigo do Artigo 28.º do GDPR. Precisa de ter um Contrato de Tratamento de Dados (DPA) em vigor. A maioria dos principais fornecedores de cloud oferece DPAs padrão, mas estes são frequentemente documentos universais que não abordam as especificidades do tratamento por LLM — particularmente no que diz respeito ao treino do modelo.
Leia a letra pequena. Muitos DPAs excluem explicitamente o treino e a melhoria do modelo das suas restrições de tratamento de dados. Essa exceção significa que o fornecedor pode treinar com os dados dos seus utilizadores, e o DPA não protege contra isso.
Transferências Transfronteiriças: Artigos 44.º a 49.º
O envio de dados pessoais para um fornecedor nos EUA ou noutro local fora do EEE requer um mecanismo jurídico ao abrigo do Capítulo V do GDPR. O Quadro de Privacidade de Dados UE-EUA abrange muitas transferências para os EUA, mas:
- Apenas abrange fornecedores certificados ao abrigo do quadro
- Foi contestado juridicamente e pode ser invalidado (como os seus antecessores foram)
- Não abrange transferências para fornecedores em outros países terceiros
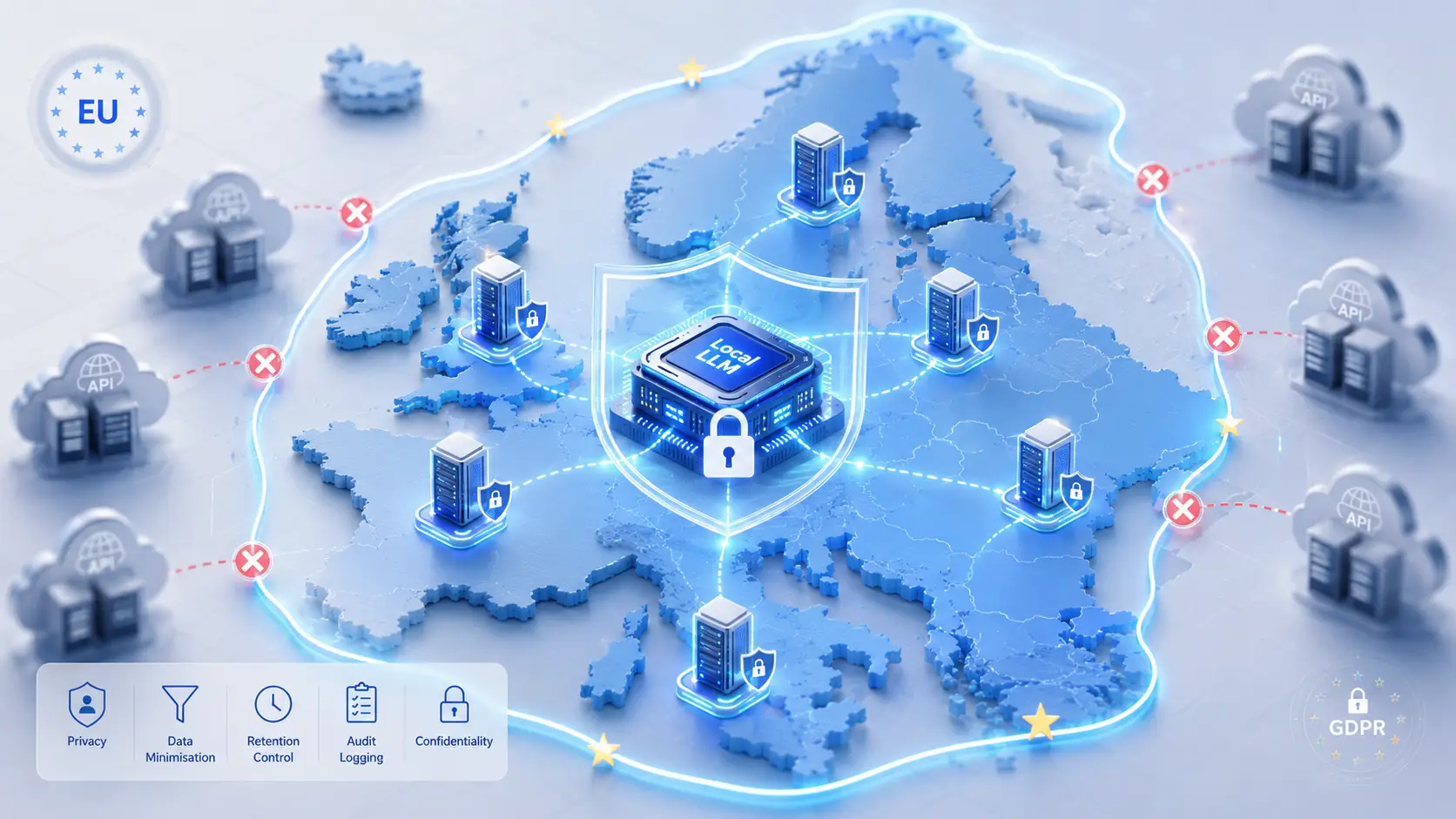
Para organizações que não podem tolerar o risco dos mecanismos de transferência, a única solução certa é manter o tratamento dentro do EEE.
A Resposta: LLM Local
Executar um LLM localmente — nos seus próprios servidores, num centro de dados da UE — elimina estruturalmente a maioria destes problemas:
- Sem subcontratante externo. Não é necessário DPA para a camada de inferência (é simultaneamente responsável pelo tratamento e subcontratante).
- Sem transferência transfronteiriça. Os dados nunca saem do EEE.
- Sem treino com os seus dados. Os pesos do modelo são estáticos; os seus dados não fluem de volta para lado nenhum.
- Conservação sob o seu controlo. Os registos são seus; as políticas de retenção aplicam-se conforme a sua configuração.
As restantes obrigações do GDPR — base jurídica, transparência, direitos dos titulares dos dados — continuam a aplicar-se. Mas não está a acrescentar uma camada inteira de conformidade de subcontratante e transferência.
Considerações Práticas
Seleção de modelos. O EULLM Hub fornece modelos pré-especializados com fichas de conformidade com o AI Act. Utilizar um modelo com proveniência documentada dos dados de treino é uma boa prática para o princípio de responsabilidade do GDPR.
Registo de auditoria. O EULLM Engine inclui registo de auditoria integrado. Manter registos das atividades de tratamento (Artigo 30.º) é simples quando controla a pilha de inferência.
Pedidos dos titulares dos dados. Se um utilizador perguntar que dados detém sobre si, ou solicitar o apagamento, a infraestrutura local torna isso exequível. Sabe exatamente o que está armazenado e onde.
Conclusão: para organizações que tratam dados pessoais com IA — o que abrange quase todos os casos de uso empresarial de IA — a infraestrutura LLM local não é apenas tecnicamente viável. Em muitos contextos, é a única opção em conformidade com o GDPR.
O EULLM Engine corre inteiramente dentro da sua infraestrutura. Veja o projeto no GitHub.