Ogólne Rozporządzenie o Ochronie Danych skończyło w 2026 roku osiem lat. Zostało napisane, gdy modele uczenia maszynowego były stosunkowo małe, a pomysł konwersacyjnej AI przetwarzającej miliony punktów danych osobowych w czasie rzeczywistym był science fiction. A jednak zasady GDPR doskonale wpisują się w wdrożenia LLM — często w sposób, który stwarza poważne problemy z compliance dla organizacji korzystających z chmurowych API AI.
Podstawowy Problem GDPR z Chmurowym LLM
Artykuł 5 GDPR określa sześć zasad przetwarzania danych osobowych. Przeanalizujmy, jak chmurowe API LLM wypadają w odniesieniu do każdej z nich:
Zgodność z prawem, rzetelność i przejrzystość. Czy Państwa użytkownicy wiedzą, że ich dane są wysyłane do zewnętrznego dostawcy AI? Czy istnieje podstawa prawna dla tego przekazania? Wiele organizacji wdrażających chatboty AI nie zastanowiło się dokładnie, czy ujawniły to w swoich informacjach o ochronie prywatności.
Ograniczenie celu. Dane zebrane w jednym celu nie powinny być używane w innym. Gdy dostawca chmury używa Państwa zapytań API do ulepszania swojego modelu, czy jest to zgodne z celami, w których Państwa użytkownicy przekazali Państwu swoje dane? Prawie na pewno nie.
Minimalizacja danych. Powinni Państwo przetwarzać wyłącznie dane, które są „adekwatne, stosowne i ograniczone do tego, co niezbędne". Wysyłanie pełnych historii konwersacji do chmurowego API, gdy wystarczyłoby podsumowanie, narusza tę zasadę.
Prawidłowość. Mniej istotna dla LLM, ale warto zauważyć, że generowane przez AI wyniki mogą tworzyć niedokładne zapisy, jeśli zostaną wprowadzone z powrotem do systemów danych.
Ograniczenie przechowywania. Dane nie powinny być przechowywane dłużej niż jest to konieczne. Polityki przechowywania danych dostawców chmury dotyczące logów wywołań API mogą nie być zgodne z Państwa obowiązkami w zakresie przechowywania.
Integralność i poufność. Muszą być zapewnione odpowiednie środki bezpieczeństwa. Wysyłanie wrażliwych danych przez internet do zagranicznego dostawcy chmury wprowadza powierzchnię bezpieczeństwa, której Państwo nie kontrolują.
Artykuł 28: Umowy Powierzenia Przetwarzania
Jeśli dostawca chmury AI przetwarza dane osobowe w Państwa imieniu, jest podmiotem przetwarzającym w rozumieniu Artykułu 28 GDPR. Muszą Państwo mieć zawartą Umowę Powierzenia Przetwarzania Danych (DPA). Większość głównych dostawców chmury oferuje standardowe DPA, ale są to często dokumenty „jeden rozmiar dla wszystkich", które nie odnoszą się do specyfiki przetwarzania LLM — szczególnie w odniesieniu do szkolenia modeli.
Proszę przeczytać drobny druk. Wiele DPA wyraźnie wyklucza szkolenie i ulepszanie modeli z ograniczeń dotyczących przetwarzania danych. To wyłączenie oznacza, że dostawca może szkolić modele na danych Państwa użytkowników, a DPA przed tym nie chroni.
Transgraniczne Przekazywanie Danych: Artykuły 44–49
Wysyłanie danych osobowych do dostawcy w USA lub poza EOG wymaga mechanizmu prawnego zgodnie z Rozdziałem V GDPR. Ramy prywatności danych UE-USA obejmują wiele przekazań do USA, ale:
- Obejmują tylko dostawców certyfikowanych w ramach tych mechanizmów
- Były kwestionowane prawnie i mogą zostać unieważnione (jak ich poprzednicy)
- Nie obejmują przekazań do dostawców w innych krajach trzecich
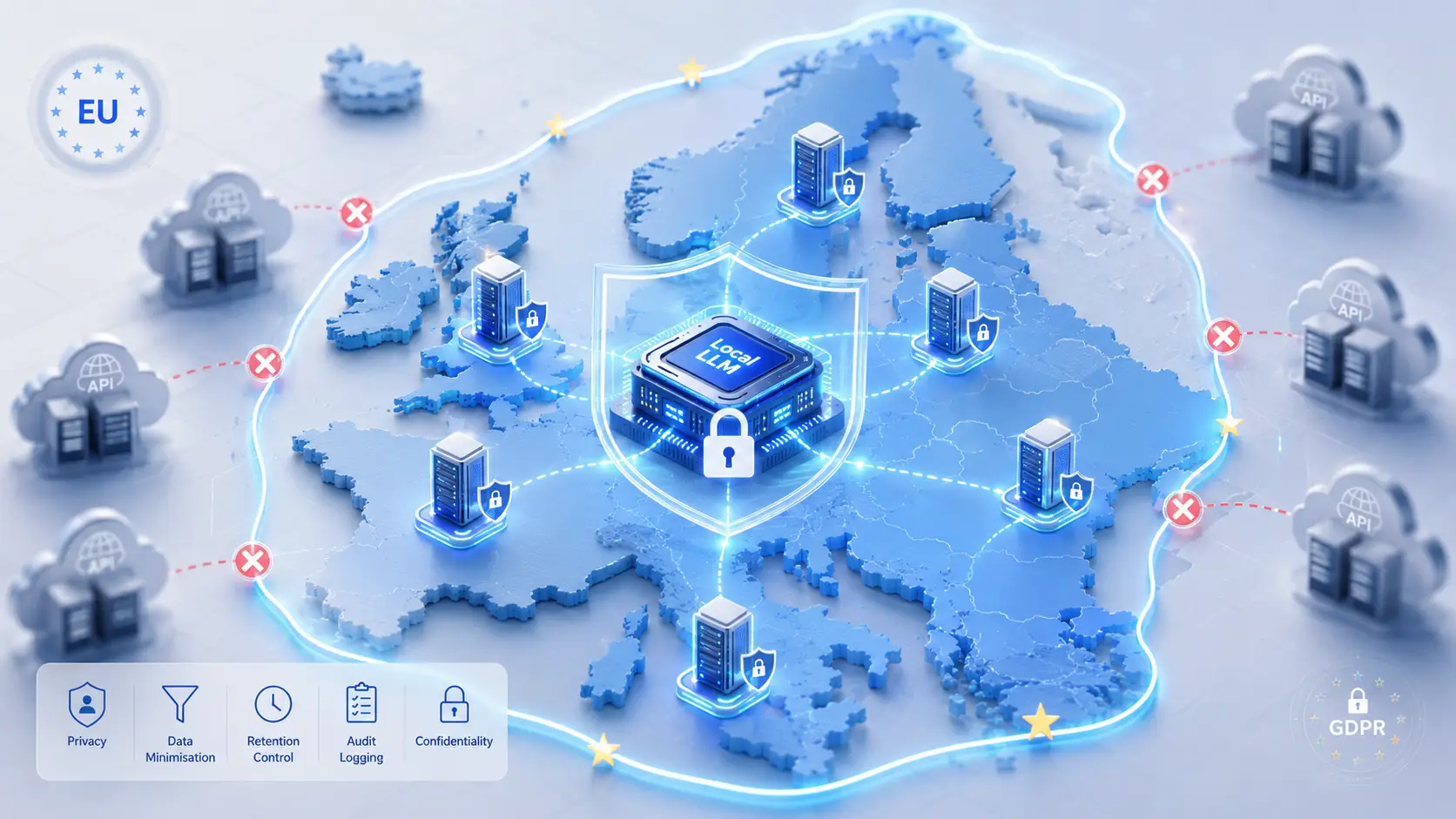
Dla organizacji, które nie mogą tolerować ryzyka mechanizmów przekazywania, jedynym pewnym rozwiązaniem jest utrzymanie przetwarzania w EOG.
Rozwiązanie: Lokalny LLM
Uruchamianie LLM lokalnie — na własnych serwerach, w centrum danych UE — strukturalnie eliminuje większość tych problemów:
- Brak zewnętrznego podmiotu przetwarzającego. Nie potrzeba DPA dla warstwy wnioskowania (Państwo są jednocześnie administratorem i podmiotem przetwarzającym).
- Brak transgranicznego przekazywania. Dane nigdy nie opuszczają EOG.
- Brak szkolenia na Państwa danych. Wagi modelu są statyczne; Państwa dane nie trafiają nigdzie z powrotem.
- Przechowywanie pod Państwa kontrolą. Logi należą do Państwa; polityki przechowywania stosują się zgodnie z Państwa konfiguracją.
Pozostałe obowiązki GDPR — podstawa prawna, przejrzystość, prawa osób, których dane dotyczą — nadal mają zastosowanie. Ale nie dokładają Państwo całej warstwy compliance dotyczącej podmiotu przetwarzającego i przekazywania danych.
Praktyczne Uwagi
Dobór modeli. EULLM Hub dostarcza wstępnie wyspecjalizowane modele z kartami zgodności z AI Act. Korzystanie z modelu z udokumentowanym pochodzeniem danych treningowych jest dobrą praktyką dla zasady rozliczalności GDPR.
Rejestrowanie audytów. EULLM Engine zawiera wbudowane rejestrowanie audytów. Prowadzenie rejestrów działań przetwarzania (Artykuł 30) jest proste, gdy kontrolują Państwo stos wnioskowania.
Żądania osób, których dane dotyczą. Jeśli użytkownik zapyta, jakie dane Państwo przechowują na jego temat lub zażąda ich usunięcia, lokalna infrastruktura sprawia, że jest to możliwe do wykonania. Wiedzą Państwo dokładnie, co jest przechowywane i gdzie.
Wniosek końcowy: dla organizacji przetwarzających dane osobowe za pomocą AI — co dotyczy prawie każdego korporacyjnego przypadku użycia AI — lokalna infrastruktura LLM nie jest tylko technicznie wykonalna. W wielu kontekstach jest jedyną opcją zgodną z GDPR.
EULLM Engine działa całkowicie w Państwa infrastrukturze. Zobacz projekt na GitHub.